

编码/加密
Base家族
base64可以换表编码
1 | 表:sQ+3ja02RchXLUFmNSZoYPlr8e/HVqxwfWtd7pnTADK15Evi9kGOMgbuIzyB64CJ |
MD5
在线网站:https://www.cmd5.com
Byte类型

emoji-AES
在线网站:https://aghorler.github.io/emoji-aes/
1 | 密文:🙃💵🌿🎤🚪🌏🐎🥋🚫😆✅🌊🚰✖😇😊🐍😀🔪😇🚰🎈🏎😂❓😁🍎👑⏩🚫❓🎅🎃😡⌨☀🍌😁✖😂🏎🍌🎃🗒 |
emoji解码
在线网站:http://www.atoolbox.net/Tool.php?Id=937
1 | 🐯👏👋🐾👚👪👇👱👞👚🐦👡👙👚👏👍🐯👏🐽👐👜🐦👇👱👜👙👤👡👙🐬👥🐻🐯👏👋👈👚👪👇👘👰👛👮👡👙👎🐭🐯 |
二维码
解码在线网站:https://cli.im/deqr/other
分析修复在线网站:https://merri.cx/qrazybox/
频次分析
字频分析:https://lzltool.cn/Tools/LetterFrequency
摩斯电码
可能只有.-或0 1组成,也可能是其他只有两种字符的情况,通常会使用空格、换行或/进行分割
维吉尼亚密码
- 给出密钥 -> CyberChef
- 没有密钥 -> 根据对照表手搓密钥
在线网站:https://ctf.bugku.com/tool/vigenere
维吉尼亚flag爆破脚本:
1 | #By C3ngH |
希尔密码
已知密文和密钥,并且密钥(key)是一个网址,如http://www.verymuch.net
已知密文和密钥,并且密钥是四个数字
1 | 密文:ymyvzjtxswwktetpyvpfmvcdgywktetpyvpfuedfnzdjsiujvpwktetpyvnzdjpfkjssvacdgywktetpyvnzdjqtincduedfpfkjssne |
在线网站:https://www.metools.info/code/hillcipher243.html
Rabbit加密
密文形式类似base64,但可能有+号
在线网站:https://www.sojson.com/encrypt_rabbit.html
幂数加密/云影密码
密文只由0 1 2 4 8组成
脚本:
1 | with open(r'C:/Users/67300/Download/1.txt','r') as f: #修改路径 |
曼彻斯特编码 & 差分曼彻斯特编码

使用曼彻斯特编码转换工具进行转换

社会主义核心价值观编码
在线网站:http://www.hiencode.com/cvencode.html
音符解密
1 | ♭♯♪‖¶♬♭♭♪♭‖‖♭♭♬‖♫♪‖♩♬‖♬♬♭♭♫‖♩♫‖♬♪♭♭♭‖¶∮‖‖‖‖♩♬‖♬♪‖♩♫♭♭♭♭♭§‖♩♩♭♭♫♭♭♭‖♬♭‖¶§♭♭♯‖♫∮‖♬¶‖¶∮‖♬♫‖♫♬‖♫♫§= |
注意:加密的密文一定是以=结尾的,如果没有需要自己加
在线网站:https://www.qqxiuzi.cn/bianma/wenbenjiami.php?s=yinyue
敲击码
基于5×5方格波利比奥斯方阵实现,不同点是是用K字母被整合到C中,因此密文的特征为1-5的两位一组的数字,编码的范围是A-Z字母字符集,字母不区分大小写。

在线网站:http://www.hiencode.com/tapcode.html
盲文
在线网站:https://www.qqxiuzi.cn/bianma/wenbenjiami.php?s=mangwen
Polybius密码

在线网站:http://www.atoolbox.net/Tool.php?Id=913
AES加密
不需要密钥
在线网站:http://tools.bugscaner.com/cryptoaes/
CyberChef中,IV设置为
\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00需要密钥 密钥不足16字节需要补齐
在线网站:https://www.sojson.com/encrypt_aes.html
工具:CaptfEncoder
埃特巴什码(Atbash)
1 | 密文:(+w)v&LdG_FhgKhdFfhgahJfKcgcKdc_eeIJ_gFN |
在线网站:https://www.metools.info/code/atbash209.html
DNA编码
1 | 密文:AATTCAACAACATGCTGC |
脚本:https://github.com/omemishra/DNA-Genetic-Python-Scripts-CTF
仿射密码
有两个key,key-a为必须是(1,3,5,7,9,11,15,17,19,21,23,25)中的一个,key-b是0~25的数字
在线网站:http://www.hiencode.com/affine.html
Brainfuck
1 | 密文:+++++ +++++ [->++ +++++ +++<] >++.+ +++++ .<+++ [->-- -<]>- -.+++ +++.< |
在线网站:https://tool.bugku.com/brainfuck/
Ook!

在线网站:https://tool.bugku.com/brainfuck/
与佛论禅 / 与熊论道 / 兽语加密
通常以佛曰和熊曰开头,中文乱码
在线网站:http://hi.pcmoe.net/
在线网站:https://ctf.bugku.com/tool/todousharp
空白格 / 无字天书:

在线网站:https://www.w3cschool.cn/tryrun/runcode?lang=whitespace
在线网站:https://vii5ard.github.io/whitespace/
Serpent解密
在线网站:https://www.ssleye.com/ssltool/ser_cipher.html
零宽隐写
在线网站:http://330k.github.io/misc_tools/unicode_steganography.html
Gronsfeld密码
1 | # 解密脚本 |
UUencode编码
有点像base85
1 | =8S4U,3DR8SDY,C`S-F5F-C(S,S<R-C`Q9F8S87T` |
在线网站:https://www.qqxiuzi.cn/bianma/uuencode.php
AAencode编码
1 | 密文: |
在线网站:http://www.hiencode.com/aaencode.html
XXencode编码
和UUencode有点像
在线网站:https://try8.cn/tool/code/xxencode
snow隐写
在行尾附加空格和制表符来隐藏 ASCII 文本中的消息
官网:https://www.darkside.com.au/snow/
| 参数 | 作用 |
|---|---|
-C |
如果隐藏,则压缩数据,或者如果提取,则会解压缩。 |
-Q |
静音模式。如果未设置,则程序报告统计信息,例如压缩百分比和可用存储空间的数量。 |
-S |
报告文本文件中隐藏消息的近似空间量。考虑线长度,但忽略其他选项。 |
-p password |
如果设置为此,则在隐藏期间将使用此密码加密数据,或在提取期间解密。 |
-l line-length |
在附加空格时,Snow将始终产生比此值短的线条。默认情况下,它设置为80。 |
-f message-file |
此文件的内容将隐藏在输入文本文件中。 |
-m message-string |
此字符串的内容将被隐藏在输入文本文件中。请注意,除非在字符串中包含一个换行符,否则在提取邮件时,否则不会打印换行符。 |
加密消息
1
SNOW.EXE -C -m "qsdz yyds" -p "duzou" infile outfile
提取消息
1
SNOW.EXE -C -p "duzou" infile outfile
需要注意的是,infile 必须在 outfile 前,如果不填 infile 选项,则默认从标准输入中获得;如果不填 outfile 选项,则默认输出到标准输出中。
中文电报
类似于四位数一组的编码
1 | 5337 5337 2448 2448 0001 2448 0001 2161 1721 1869 6671 0008 3296 4430 0001 3945 0260 3945 1869 4574 5337 0344 2448 0037 5337 5337 0260 0668 5337 6671 0008 3296 1869 6671 0008 3296 1869 2161 1721 |
在线网站:https://www.qqxiuzi.cn/bianma/dianbao.php
Quote-Printable编码
1 | 密文:=E6=8A=80=E6=9C=AF=E6=9C=89=E6=B8=A9=E5=BA=A6 |
在线网站:https://try8.cn/tool/code/qp
中文ASCII码
1 | 27880 30693 25915 21892 38450 23454 39564 23460 21457 36865 112 108 98 99 116 102 33719 21462 21069 27573 102 108 97 103 20851 27880 79 110 101 45 70 111 120 23433 20840 22242 38431 22238 22797 112 108 98 99 116 102 33719 21462 21518 27573 102 108 97 103 |
加上 & # ;
1 | 注知攻善防实验室发送plbctf获取前段flag关注One-Fox安全团队回复plbctf获取后段flag |
在线网站:https://www.xuhuhu.com/beautify/ascii/
培根密码
由 a、b 或者 A、B 或者 0、1 组成的密文,密文中只有两种字符,可以直接使用 随波逐流 解密
CyberChef 的培根密码解密可能会有点问题,这里建议用随波逐流解密
锟斤拷
成因是 Unicode 的替换字符(Replacement Character,�)于 UTF-8 编码下的结果 EF BF BD 重复,在 GBK 编码中被解释为汉字 “锟斤拷”(EF BF BD EF BF BD)
1 | import os |
键盘坐标密码
1 | 1 2 3 4 5 6 7 8 9 0 |
11 21 31 18 27 33 34 -> QAZIJCV
福尔摩斯 跳舞的小人
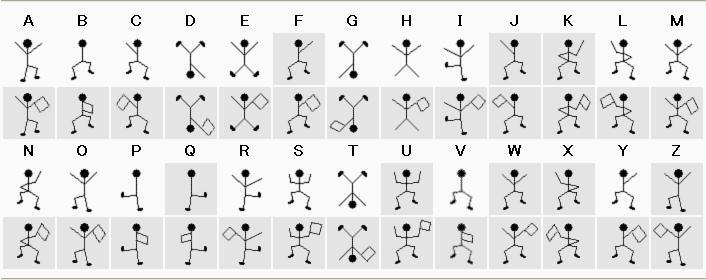
手机九宫格键盘密码
82 73 42 31 22 31 33 41 32
U R H D B D F G E
利用编程代码画图
- LOGO编程语言【例题-[RCTF2019]draw 】
在线编译器:https://www.calormen.com/jslogo/ - CFRS编程语言【例题-2024宁波市赛初赛 Misc2】
在线画图网站:https://susam.net/cfrs.html
spammimic编码
HGAME 2024有一题,可识读英文可以转成中文乱码,ROT8000编码
强网拟态2024 OSINT也是
malbolge
类似这样的
1 | ('&%:9]!~}|z2Vxwv-,POqponl$Hjig%eB@@>}=<M:9wv6WsU2T|nm-,jcL(I&%$#" |
类似题:2024 强网拟态 PvZ
在线网站:Malbolge - interpreter online (doleczek.pl)
PDU编码
1 | 0011000D91683106019196F40008AA104F60597D0067006F006F0064000A0033 |
解码工具
Ciphey
1 | ciphey -t "aGVsbG8gbXkgbmFtZSBpcyBiZWU=" #WSL |
CyberChef
Basecrack
1 | python3 basecrack.py -m |

随波逐流
文件头
1 | .zip的文件头:50 4B 03 04 14 00 08 00 |
图片通用隐写
属性-详细信息
Hint或Key可能藏在属性里
010Editor检查文件末尾
flag可能藏在文件末尾
010Editor检查文件头
可能存在文件头和文件后缀名不一致导致打不开的情况
binwalk & foremost
binwalk查看,foremost提取
盲水印隐写
项目地址:https://github.com/chishaxie/BlindWaterMark
1 | bwm.py 程序文件python2版本 |
1 | python bwm.py encode hui.png wm.png hui_with_wm.png #加密 |
1 | python bwm.py decode hui.png hui_with_wm.png wm_from_hui.png #解密 |
频域盲水印
Puzzle Solver一把梭
图片分离 / 拼接
1 | #WSL |
OurSecret隐写
拖进OurSecret输入密钥进行解密
拼图
碎图片合成一张图片
1 | #在Windows中使用imagemagick处理 |
1 | #在kali中处理 |
然后把上面合成好的图片使用 Puzzle-Merak 工具进行智能拼图


输入 generation、population、size 并用分号分开即可开始自动拼图
也可以使用gaps智能拼图(在kali和wsl里使用都可以)
1 | gaps --image=out.png --generation=30 --population=144 --size=30 --save |
1 | gaps --image=flag.jpg --generations=50 --population=180 --size=125 --verbose |
近邻法缩放图片
在PS中打开图片,然后在更改图像大小中,将宽高调成指定像素并将重新采样选项选为邻近(硬边缘)
pixeljihad
pixeljihad隐写 有密码
在线网站:https://sekao.net/pixeljihad/
隐写文本藏在原图片和隐写文件中间
在010 Editor中搜索IEND,查看后面有没有额外内容
提取图片中等距的像素点得到隐写的图片
在PowerShell中运行Get_Pixels.py
1 | #Get_Pixels.py |
1 | py main.py -f arcaea.png -p 0x0+3828x2148 -n 12x12 |
silenteye隐写
特征:放大图像后会有行列不对齐的小灰块
直接用 silenteye 打开输入密钥decode即可,默认密钥是 silenteye
图片报错改宽高后图片无变化
再 foremost 一下
DeEgger Embedder隐写
使用 DeEgger Embedder 工具 extract files
EXIF隐写
直接在 WSL 中输入以下命令查看即可,也可以直接使用 破空 flag 查找工具 进行查找
1 | exiftool 1.jpg |
npiet
Gabrielle Singh Cadieux - Piet IDE
1 | npiet.exe -tpic image.png |
猫脸变换
1 | import matplotlib.pyplot as plt |
PNG图片隐写
CRC错误
修改宽高,17~20是宽,21~24是高
可用Puzzle Solver一把梭修改
LSB隐写
1 | # wsl |
信息藏在图片中有时候会看不出来,所以还是要用stegsolve.jar过一遍
cloacked-pixel
lsb隐写的可能是加密后的数据,i春秋最喜欢的cloacked-pixel
拉到kali/WSL里用cloacked-pixel命令解密出数据
1 | python2 cloacked-pixel-master/lsb.py extract 0.png out.data f78dcd383f1b574b |
0.png是隐写后的图片;out.data是隐写内容保存的位置;f78dcd383f1b574b是密钥
IDAT块隐写
拉到kali里用pngcheck -v 0.png检查IDAT
解压zlib获得原始数据
然后用010提取数据扔进zlib脚本解压获得原始数据
将异常的IDAT数据块斩头去尾之后使用脚本解压,在python2代码如下:
1 | import zlib |
加上文件头爆破宽高得到新的图片
一般出问题的 IDAT Chunk 大小都是比正常的小的,很可能在图片末尾
如果不确定是哪一个有问题,可以尝试都提取出来,一个一个分析
可以使用 tweakpng 辅助分析,但是一般用010的模板提取分析就够了
apngdis_gui
一张png图片还可能是apng,直接用apngdis_gui跑一下,可以分出两张相似的png
CVE-2023-28303 截图工具漏洞
可以使用Github上大佬写好的工具一把梭,前提是需要知道原图的分辨率
stegpy隐写
stegpy 开源地址 下载好后直接用WSL输入以下命令并输入密码解密即可
也可以直接用 pip 安装: pip3 install stegpy
1 | stegpy 1.png -p |
JPG图片隐写
outguess隐写
项目地址:https://github.com/crorvick/outguess
1 | #WSL安装 |
加密
1 | outguess -k “my secret key” -d hidden.txt demo.jpg out.jpg |
解密
1 | outguess -k “my secret key” -r out.jpg hidden.txt |
F5-steganography-master(F5隐写)
项目地址:https://github.com/matthewgao/F5-steganography
1 | #有密码的情况 |
JPHS隐写
有可能会有密码
导出步骤 Select File –> seek –> demo.txt –> Save the file
steghide隐写
1 | #密码已知 |
在WSL或者kali里用Stegseek跑(字典在wordlist里)
1 | #密码未知 |
1 | #或者在WSL或者kali里用Stegseek跑(字典在wordlist里) |
BMP图片隐写
宽高爆破
删除文件头,并保存为文件名.data,然后用GIMP打开修改宽高(比较方便)
或者直接用bmp爆破脚本跑 python script.py -f filename.bmp
1 | #用这个脚本要注意对图片一个个使用 |
1 | import os |
wbStego4open隐写
用wbStego4open直接decode
GIF隐写
分帧提取 在线网站:https://tool.lu/gifsplitter/
1 | # 在Windows或者WSL中执行以下命令进行分离 |
二维码隐写
bmp转二维码
16进制转pyc
字符串制作二维码
直接右键使用B神的脚本制作二维码,制作前注意要把字符串的长度手动修正为平方数
1.0 1制作二维码
2.00 11制作二维码四个TTL值转换一个字节的二进制数
Aztec code、DataMatrix、GridMatrix、汉信码、PDF417code等
Webp隐写
webp文件用电脑自带的图片看可能会有点问题,建议用浏览器打开这种文件
webp可能是动图,可以用下面这个脚本分离webp中的每帧图片
1 | from PIL import Image |
RAW、ARW文件隐写
ARW文件是 Sony 相机的原始数据格式
可以使用 rawpy 模块读取图片的像素数据,查看是否存在LSB隐写【例:2024 L3HCTF RAWatermark】
示例脚本如下:
1 | import rawpy |
压缩包
Tips:压缩包的密码可以是中英文字符和符号
没有思路时可以直接纯数字/字母暴力爆破一下
zip文件结构
三部分:压缩文件源数据区 + 压缩源文件目录区 + 压缩源文件目录结束标志
文件源数据区
| HEX 数据 | 描述 | 010Editor 模板数据 |
|---|---|---|
| 50 4B 03 04 | zip 文件头标记,看文本的话就是 PK 开头 | char frSignature[4] |
| 0A 00 | 解压文件所需 pkware 版本 | ushort frVersion |
| 00 00 | 全局方式位标记(有无加密),头文件标记后 2bytes | ushort frFlags |
| 00 00 | 压缩方式 | enum COMPTYPE frCompression |
| E8 A6 | 最后修改文件时间 | DOSTIME frFileTime |
| 32 53 | 最后修改文件日期 | DOSDATE frFileDate |
| 0C 7E 7F D8 | CRC-32 校验 | uint frCrc |
文件目录区
| HEX 数据 | 描述 | 010Editor 模板数据 |
|---|---|---|
| 50 4B 01 02 | 目录中文件文件头标记 | char deSignature[4] |
| 3F 00 | 压缩使用的 pkware 版本 | ushort deVersionMadeBy |
| 0A 00 | 解压文件所需 pkware 版本 | ushort deVersionToExtract |
| 00 00 | 全局方式位标记(有无加密),目录文件标记后 4bytes | ushort frFlags |
| 00 00 | 压缩方式 | enum COMPTYPE frCompression |
| E8 A6 | 最后修改文件时间 | DOSTIME frFileTime |
| 32 53 | 最后修改文件日期 | DOSDATE frFileDate |
| 0C 7E 7F D8 | CRC-32 校验 | uint frCrc |
文件目录结束
| 50 4B 05 06 | 目录结束标记 | char elSignature[4] |
|---|---|---|
| 00 00 | 当前磁盘编号 | ushort elDiskNumber |
| 00 00 | 目录区开始磁盘编号 | ushort elStartDiskNumber |
rar文件结构
| HEX 数据 | 描述 | 010Editor 模板数据 |
|---|---|---|
| 52 61 72 21 1A 07 00 | rar 文件头标记,文本为 Rar! |
Main block
| HEX 数据 | 描述 | 010Editor 模板数据 |
|---|---|---|
| 33 92 B5 E5 | 全部块的 CRC32 值 | uint32 HEAD_CRC |
| 0A | 块大小 | struct uleb128 HeadSize |
| 01 | 块类型 | struct uleb128 HeadType |
| 05 | 阻止标志 | struct uleb128 HeadFlag |
File Header
| HEX 数据 | 描述 | 010Editor 模板数据 |
|---|---|---|
| 43 06 35 17 | 单独块的 CRC32 值 | uint32 HEAD_CRC |
| 55 | 块大小 | struct uleb128 HeadSize |
| 02 | 块类型 | struct uleb128 HeadType |
| 03 | 阻止标志 | struct uleb128 HeadFlag |
Terminator
| HEX 数据 | 描述 | 010Editor 模板数据 |
|---|---|---|
| 1D 77 56 51 | 固定的 CRC32 值 | uint32 HEAD_CRC |
| 03 | 块大小 | struct uleb128 HeadSize |
| 05 | 块类型 | struct uleb128 HeadType |
| 04 00 | 阻止标志 | struct uleb128 HeadFlag |
压缩包伪加密
zip文件:
可以直接用ZipCenOp.jar修复:
java -jar ZipCenOp.jar r screct.zip
WinRAR打开、010改标志位、binwalk直接分离
如果压缩文件已损坏,则尝试用winrar打开,工具-修复压缩包
压缩源文件数据区:7-8位表示有无加密
压缩源文件目录区:9-10位表示是否是伪加密
一般这俩地方都是09 00的,大概率就是伪加密了(直接把第二个PK后的09改了就行)
奇数为加密,偶数为不加密,frflag位
frFlags 用于告知压缩软件这个压缩包的一些信息,奇数(最低位为1)告诉压缩软件这个压缩包是被加密的。没有一个标志可以判断是否是伪加密,因为生活实际中根本就没有这样的需求。我们只能猜测这个 CTF 题目中,通过修改 frFlags,将未加密压缩包标记成了已加密。
7zip判断是否为加密是看record区的frflag位,bandzip和winrar判断是否为加密是看是看direntry区的deflag位,所以在出题的时候需要把两个位置同时修改。
rar文件:
第24个字节尾数为4表示加密,0表示无加密,将尾数改为0即可破解伪加密
CRC爆破(压缩包中文件比较小的时候)
使用CRC爆破需要文件大小小于等于18个字节
参考文章:https://blog.csdn.net/mochu7777777/article/details/110206427
可以使用CTFD中的两种脚本爆破一下(速度不同)
明文攻击
已知所有的明文或三段密钥
使用Advanced Archive Password Recovery破解
有和压缩包中的一样(CRC值一样)的文件时,压缩然后用AAPR进行明文攻击,这个攻击的过程可能需要几分钟
有了完整的三段密钥也可以使用这个工具破解密码
使用bkcrack破解
1 | #将bkcrack作为系统命令使用 |
1 | 命令的格式为:bkcrack -C 加密的压缩包 -c 存在明文的文件 -p 存储了明文的文本 |
已知部分明文
利用bkcrack进行攻击
参考资料
1 | https://www.freebuf.com/articles/network/255145.html |
该利用方法的具体要求如下:
1 | 至少已知明文的12个字节及偏移,其中至少8字节需要连续。 |
如何判断压缩工具(参考自B神的博客)
| 压缩攻击 | VersionMadeBy(压缩所用版本) |
|---|---|
| Bandzip 7.06 | 20 |
| Windows自带 | 20 |
| WinRAR 4.20 | 31 |
| WinRAR 5.70 | 31 |
| 7-Zip | 63 |
bkcrack常用参数
1 | -c 要解密的文件 |
例题:
1 | #Tips: |
1)简单的加密文本压缩包破解
1 | flag{16e371fa-0555-47fc-b343-74f6754f6c01} |
1 | #攻击步骤如下: |
1 | #-p 指定的明文不需要转换,-x 指定的明文需要转成十六进制 |
2)利用PNG图片文件头破解
1 | #准备已知明文 |
3)利用压缩包格式破解
1 | 将一个名为flag.txt的文件打包成ZIP压缩包后,发现文件名称会出现在压缩包文件头中,且偏移固定为30。且默认情况下,flag.zip也会作为该压缩包的名称。 |
1 | echo -n "flag.txt" > plain1.txt #-n参数避免换行,不然文件中会出现换行符,导致攻击失效 |
Tips:如果这里用”XXXXX.txt”作为plaint1.txt无法破解出密钥,可以试试直接去掉后缀再作为plaint1.txt
例如:NKCTF2023——五年Misc,三年模拟
1 | #echo -n "handsome.txt" > plain1.txt 破解失败 |
4)EXE文件格式破解
1 | EXE文件默认加密情况下,不太会以store方式被加密,但它文件格式中的的明文及其明显,长度足够。如果加密ZIP压缩包出现以store算法存储的EXE格式文件,很容易进行破解。 |
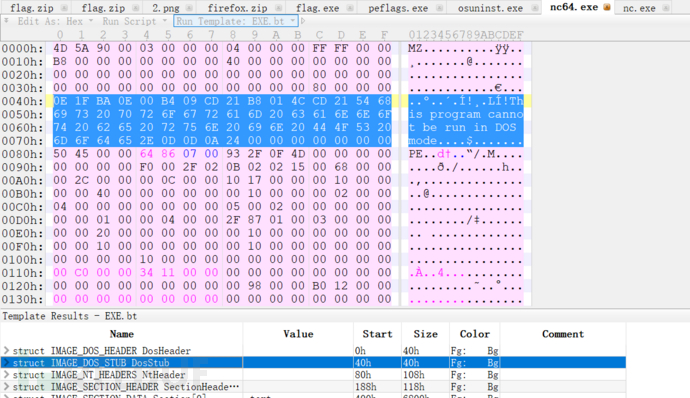
1 | echo -n "0E1FBA0E00B409CD21B8014CCD21546869732070726F6772616D2063616E6E6F742062652072756E20696E20444F53206D6F64652E0D0D0A2400000000000000" | xxd -r -ps > mingwen |
5)流量包pcapng格式解密
1 | echo -n "00004D3C2B1A01000000FFFFFFFFFFFFFFFF" | xxd -r -ps > pcap_plain1 |
6)网站相关文件破解
1 | robots.txt的文件开头内容通常是User-agent: * |
1 | echo -n '<?xml version="1.0" encoding="UTF-8"?>' > xml_plain |
7)SVG文件格式破解
1 | #SVG是一种基于XML的图像文件格式 |
8)VMDK文件格式破解
1 | echo -n "4B444D560100000003000000" | xxd -r -ps > plain2 |
有时候直接给你部分明文的情况(2023 DASCTFxCBCTF)
直接在bkcrack中使用以下命令即可,key是题目给的压缩包中被压缩文件的部分明文
1 | bkcrack -C purezip.zip -c 'secret key.zip' -p key |
直接给了加密压缩包中部分文件的情况
例题1 - 2023 古剑山-幸运饼干
可以先把该文件用压缩软件压缩成一个压缩包,然后用 Advanced Archive Password Recovery 明文攻击试试看
用压缩软件把该文件压缩成一个压缩包,然后使用 bkcrack 进行明文攻击
为什么需要压缩成压缩包呢?因为如果不带上压缩包进行明文攻击的话会报下面这个错误
1
2
3$ bkcrack -C flag.zip -c 'hint.jpg' -p hint.jpg
bkcrack 1.5.0 - 2023-03-08
Data error: ciphertext is smaller than plaintext.用 -P 参数带上压缩包后即可正确解密出密钥
1
2
3
4
5
6
7
8
9$ bkcrack -C flag.zip -c hint.jpg -p hint.jpg -P hint.zip
bkcrack 1.5.0 - 2023-03-08
[14:37:27] Z reduction using 25761 bytes of known plaintext
100.0 % (25761 / 25761)
[14:37:29] Attack on 289 Z values at index 21821
Keys: afb9fee3 f8795353 f6de1d4e
100.0 % (289 / 289)
[14:37:29] Keys
afb9fee3 f8795353 f6de1d4e因此这种情况一定要记得将已有的文件用适当的压缩方法压缩成压缩包,然后用-P参数带上这个压缩包
例题1 - 2023 铁三决赛-baby_jpg
我们先从部分伪加密的压缩包中分离出了 serect.pdf,然后从PDF中 foremost 出了加密压缩包中的 sha512.txt
将 sha512.txt 压缩成 sha512.zip,然后使用下面的命令进行明文攻击即可:
其中 -C 后是要破解的压缩包,-c 后是压缩包中我们要破解的文件,-P 后是我们压缩好的压缩包,-p 后是我们已得的文件
1 | $ bkcrack -C 00000218.zip -c 'sha512.txt' -P sha512.zip -p sha512.txt |
破解出密钥后,用 -U 参数修改压缩包密码并导出
1 | $ bkcrack -C 00000218.zip -k ed3fb6a9 1c4a7211 c07461ed -U out.zip 111 |
在比赛中的使用记录
2022 西湖论剑zipeasy
1 | bkcrack -C zipeasy.zip -c dasflow.zip -x 30 646173666c6f772e706361706e67 -x 0 504B0304 > 1.log & |
2023 DASCTFxCBCTF
利用bkcrack反向爆破密钥
1 | bkcrack -k e48d3828 5b7223cc 71851fb0 -r 3 \?b |
然后如果要对得到的密钥进行MD5加密,可以使用CyberChef(From Hex + MD5)

Tips:题目做不出来可以尝试多换几个压缩软件:Bandzip、Winrar、7zip、360压缩、2345压缩等
暴力破解(爆破时注意限制长度)
可以使用 Advanced Archive Password Recovery 进行爆破
(1) 如果知道部分的密码,可以使用掩码攻击,例如:????LiHua
(2) 没啥思路的时候可以直接用纯数字密码爆破看看,也可以用字典爆破
(3) 如果爆破的速度很慢,可以用 Passware Kit Forensic 2021 v1 (64-bit) 来爆破(也可以自定义字典)
连环套压缩包
可以用fcrackzip进行爆破或者使用CTFD中的脚本爆破
1 | import zipfile |
未知后缀的压缩包
可以多用几个压缩软件试试,比如Winrar 7z
分卷压缩包合并
1 | copy /B topic.zip.001 + topic.zip.002+topic.zip.003+topic.zip.004+topic.zip.005+topic.zip.006 topic.zip |
压缩包炸弹
很小的压缩文件,解压出来会占据巨大的空间,甚至撑爆磁盘
处理方法:010中直接编辑压缩包文件,看看是否藏有另一个压缩包
根据010中的模板修改了某些参数
有些题目可能会修改源数据中压缩包文件中被压缩文件的文件名的长度
源数据中被压缩文件名字的长度对不上也会导致解压后文件无法打开
所以…010的模板功能真的非常非常的好用!

压缩包密码是不可见字符
字节数很短的情况
直接写个Python脚本爆破即可
1 | import zipfile |
字节数较长的情况
需要先把密码base64编码一下,然后再base64解码成byte类型作为密码
1 | import base64 |
PDF隐写
直接binwalk或者foremost解出隐藏文件
可能是wbStego4open隐写,用wbStego4open直接decode
PDF中可能携带了什么文件,可以在Firefox或者别的PDF软件中打开并提取
PDF中可能有透明的文字,直接全选复制然后粘贴到记事本中查看即可
DeEgger Embedder隐写,可以直接使用 DeEgger Embedder 工具 extract files
部分PDF可以用Photoshop打开,关键信息可能隐藏在下面的图层里,例如
2024 古剑山 - jpg,尤其是Adobe Acrobat Pro出现提示:无法选择文本,这是扫描的PDF,因此您无法选择和复制文本,要运行文本识别 (OCR) 以选择文本吗?

MS-Office隐写
Excel文件:.xls .xlsx
拉入010或者记事本,查找flag
取消隐藏先前隐藏的行和列
条件格式里设置突出显示某些单元格(黑白后可能会有图案)
要先将数据按照行列排序后再进行处理
Word文件:.doc .docx
直接foremost出隐藏文件
与宏有关系的各种攻击与隐写
分析word中的宏需要用到这样一个工具:oletools
这个工具直接在pip中安装即可使用: pip3 install oletools
doc格式可以不需要文档密码直接提取其中的vba宏代码
安装好oletools后直接运行以下代码提取即可,可能加密文档的加密算法就在期中
1
olevba attachment.doc > test.txt
利用行距来隐写(例:ISCC2023-汤姆历险记)
word中可能有一段是1倍行距,可能又有一段是1.5倍行距,需要根据不同行距敲出摩斯电码(单倍转为.多倍转为-空行转为空格或者分隔符)
TXT文本隐写
NTFS流隐写
直接用NtfsStreamsEditor2扫描所在文件夹,然后导出文件
注意有关NTFS数据流的压缩包要使用WinRAR解压,否则可能遇到扫不出来的情况
wbStego4open隐写
用wbStego4open直接decode(可能有密钥)
无字天书(whitespace)&snow隐写
在线网站:https://vii5ard.github.io/whitespace/
snowdos32工具目录下运行SNOW.EXE -C -p password flag.txt命令即可垃圾邮件隐写(spammimic)
HTML隐写
- wbStego4open隐写
流量分析
拿到流量包后,第一件事就是可以先 strings | grep flag{ 一下,说不定 flag 就直接出了
当然也可以使用凤二西师傅的 破空_flag查找工具3.5.exe 来搜索 flag
WireShark基础
刚刚接触流量分析的同学可能会不太清楚 wireshark 的过滤器如何使用
但是用熟悉了其实很简单
常见的协议比如 http ,常用的有下面这些参数,其实只要在过滤器中输入 http. 它就会自动提示你了
1 | http.request.method == "POST" |
还有一些比较常用的
1 | # 包含什么内容的帧 |
其实这里可以直接右击想要过滤的字段,然后作为过滤器选中,上面就会自己跳出来过滤的表达式了(这里也可以使用或选中和且选中)
有了这个表达式,就可以带入下面的 tshark 命令一键提取所有过滤出来的帧的指定字段的数据了

tshark使用教程
导出流量包中所有POST数据包的data数据
1 | tshark -r 1.pcapng -Y "http.request.method == POST" -T fields -e data.data > data.txt |
导出HTTP数据包中所有的数据
1 | tshark -r 1.pcapng -Y "http" -T fields -e http.file_data > data.txt |
可以使用 uniq 参数去除重复行
1 | tshark -r 1.pcapng -Y "dns" -T fields -e dns.qry.name | uniq > data.txt |
流量分析基础考点
- wireshark提取数据流:
可以用tcpxtract工具:tcpxtract -f 1.pcap
strings webshell.pcapng | grep {
//打印出文件中所有可打印字符
协议分级+导出HTTP对象
流量包端口隐写(可能会有01互换)
TCP/FTP协议传输文件(binwalk和foremost都没用):
- 直接用wireshark导出为pcap文件然后用networkminer分析
- 拉入kali用tcpxtract提取文件:tcpxtract -f +文件名.pcap
- 直接追踪流提取16进制,根据文件头尾提取出文
有时候可能需要分版本分别导出
可能可以直接搜索flag明文或者编码加密过的flag
搜索flag脚本,待改进。。。
1 | #Python2 的脚本 |
USB流量分析
4字节为鼠标流量,8字节为键盘流量。
数据部分在Leftover Capture Data域中
**一些奇技淫巧:**Alt键+数字键分析,可以获得ASCII码

键盘流量分析
例题5:键盘流量分析
先在wsl或者别的虚拟机中用tshark提取数据
1 | #提取数据的命令,这里用正则表达式剔除了空行 |
Tips:老版本的tshark提取数据是有冒号的,新版本就没有冒号了,所以需要我们自己添加冒号
1 | #给键盘流量数据添加冒号.py |
加完冒号以后我们就可以直接用脚本翻译数据了
1 | #翻译键盘数据1.py |
1 | #翻译键盘数据2.py |
提取出来的数据如果有<SPACE><DEL><RET>,我们可以用vscode中的正则匹配来替换他们
鼠标流量
例题6:键盘流量分析
前两步和键盘流量一样,提取数据并加冒号,但是这里要注意判断数据的长度
1 | #给数据添加冒号.py |
根据加完冒号的数据获取坐标
1 | #获取鼠标坐标.py |
之后可以用gnuplot或者用python脚本画图
1 | #gnuplot画图命令 |
1 | #根据坐标画图.py |
如果图片是反的或者是镜像的,可以用PS处理一下
数位板流量分析:
先导出数据
tshark -r hard_Digital_plate.pcapng -T fields -e usbhid.data | sed ‘/^\s*$/d’ > out.txt
#提取并去除空行
类似于:
1 | 08803708951e000000000000 |
第二个字节代表了是否启用0x81位有效坐标,同时后四位还有数位板的压感值。
当第二字节为0x81时,说明数位板正在作画,且第8字节和第9字节存在压感值,当第二字节为0x80时,说明数位板没有落笔,即没有作画,此时第8字节和第9字节不存在压感,为0x0000。
坐标分析直接说结论,第5-8位是x轴坐标,第9-12位是y轴坐标,并且是小端序储存方法。
例如:
08803708951e000000000000这个数据,0x3708是x坐标信息,0x951e是y坐标信息,但是由于数据为小端序储存,实际x坐标为0x0837,y坐标为0x1e95。
分析数据,分为压感和低压感的数据,直接用CTFD中的脚本跑出坐标并画图
1 | #数位板压感数据分析.py |
1 | #数位板低压感数据分析.py |
SQL注入流量分析
可以使用 wireshark 的过滤器过滤出注入的流量,然后导出特定分组
然后使用 tshark 根据字段名提取出所有的注入语句
如果是盲注的话,直接写个正则匹配脚本提取数据即可
例题1-2023 铁三 traffic
Webshell流量分析
Tips:如果返回的响应数据是gzip格式,要注意提取的位置,gzip数据一般是以 1F 8B 08 00 开头的
菜刀流量分析
在TCP和HTTP协议中寻找线索,找返回包中一大串的数据,并根据标志位判断文件类型
如果是加密了的压缩包,看看是不是伪加密
哥斯拉流量分析
3.03版本
哥斯拉的连接需要填写密码和密钥,加密过程中使用的是密钥MD5的前16位
Request解密脚本
1 |
|
Response解密脚本
1 |
|
解密的例子
request解密
1 | echo encode(base64_decode(urldecode('DlMRWA1cL1gOVDc%2FMjRhVAZCJ1ERUQJKKl9TXQ%3D%3D')), $key); |
Response解密
1 | echo gzdecode(encode(base64_decode(urldecode('fL1tMGI4YTljMn75e3i2GMoehBqscKzwshr9GtI2YQRVyPwjYjhh')), $key)); |
冰蝎流量分析
简要加密过程(请求)
base64 -> AES(key = ??? IV = 0123456789abcdef) -> base64
有时候 IV = \x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00
简要解密过程(响应)
解密过程反过来即可
从流量包中的HTTP数据包中获取key和data,然后用CyberChef解密即可



这里如果想要偷懒,对于冰蝎和哥斯拉流量可以直接用 风二西 师傅的 承影_哥斯拉冰蝎解码工具 一把梭了
直接将木马中的密钥复制到工具中,然后 Ctrl+A 全选加密的数据,再右键选择对应的解密方式即可

蚁剑流量分析
蚁剑流量分析需要注意的地方:
1、路径base64字符串需要去除前两个字符后再解码
2、响应数据的头尾有额外的字符,需要先去除然后再base64解码
蚁剑webshell样本
1 |
|
这里总结一下我手动分析蚁剑流量的步骤:
1、首先url解码请求包,然后base64解码其中的php文件和该文件执行的命令
2、找到php文件中asoutput函数的标识字符串
1 | function asoutput() |
3、根据gzip的文件头提取响应包,去除标识字符串后base64解码得到响应数据
4、按照上面的步骤逐个分析流量包
CobalStrike流量分析
先从流量包中导出key文件
然后在 cs-scripts中运行 python3 parse_beacon_keys.py 得到私钥
1 | -----BEGIN PRIVATE KEY----- |
在数据包的HTTP请求中获得Cookie,然后修改CS_Decrypt中的 Beacon_metadata_RSA_Decrypt.py 的私钥和Cookie
运行即可得到 AES和HMAC key
1 | AES key:ef08974c0b06bd5127e04ceffe12597b |
然后把这两个key填入 Beacon_Task_return_AES_Decrypt.py 中
把流量包中的POST数据包中的data的值用CyberChef (from hex+to base64) 处理后得到的数据填入上面那个脚本中
一个个解密每个POST数据包中的data即可得到flag
NTLM流量分析
NTLM流量分析需要的信息,在追踪流中是找不到的,需要我们深入分析具体的每个流量包
可以用关键字 ntlmssp 过滤流量包,然后看每个流量包右侧的 info 栏快速定位NTLM信息的位置
提取 NTLMv2 哈希值并破解(SMB协议)
首先,使用关键字 ntlmssp 对流量包进行筛选并定位到认证成功的 NTLMSSP_AUTH 包
打开流量包中的 Security Blob 层
复制用户名、域名
然后,分析NTLM响应部分,找到NTProofStr字段和NTLMv2的响应,将它们作为十六进制字符串复制到文本文档中
NTLMv2 Response是从ntlmProofStr开始,因此从NTLMv2的响应中要删除ntlmProofStr。
最后,在过滤器中输入ntlmssp.ntlmserverchallenge,查找NTLM Server Challenge字段,通常这个数据包是在NTLM_Auth数据包之前,将该值作为十六进制字符串复制到文本文档。
把上面三部分的参数按以下格式保存到hash.txt
1 | username::domain:ServerChallenge:NTproofstring:modifiedntlmv2response |
1 | administrator::WIN2008:9a88373dbb4f5e36:4eb74543b9962bb2ca36e938909bb930:0101000000000000d23c83f972f7d9015e866dc6343b804400000000020008004800410043004b000100040044004300040010006800610063006b002e0063006f006d0003001600440043002e006800610063006b002e0063006f006d00050010006800610063006b002e0063006f006d0007000800d23c83f972f7d9010600040002000000080030003000000000000000000000000030000046fc5f0d124bc9b99b5b560c14cd7c7e217f08f22ef5f223679ec2c576230fa30a001000000000000000000000000000000000000900240063006900660073002f003100390032002e003100360038002e00310036002e0031003000000000000000000000000000 |
最后使用 hashcat 进行爆破
1 | hashcat -m 5600 hash.txt rockyou.txt |
1 | $ hashcat -m 5600 hash.txt rockyou.txt --show |
提取 NTLMv2 哈希值并破解(HTTP协议)
大致步骤和SMB协议的差不多,就是NTLM信息放在了 hypertext transport protocol 中
按照之前的步骤提取出来,然后 hashcat 爆破即可
1 | username::domain:ServerChallenge:NTproofstring:modifiedntlmv2response |
1 | jack::WIDGETLLC:2af71b5ca7246268:2d1d24572b15fe544043431c59965d30:0101000000000000040d962b02edd901e6994147d6a34af200000000020012005700490044004700450054004c004c004300010008004400430030003100040024005700690064006700650074004c004c0043002e0049006e007400650072006e0061006c0003002e0044004300300031002e005700690064006700650074004c004c0043002e0049006e007400650072006e0061006c00050024005700690064006700650074004c004c0043002e0049006e007400650072006e0061006c0007000800040d962b02edd90106000400020000000800300030000000000000000000000000300000078cdc520910762267e40488b60032835c6a37604d1e9be3ecee58802fb5f9150a001000000000000000000000000000000000000900200048005400540050002f003100390032002e003100360038002e0030002e0031000000000000000000 |
提取 NTLMv2 哈希值并破解(SMTP协议)
这里的NTLM流量信息可能base64编码过了,所以分析前需要base64解码:

后续步骤就和之前一样了,提取信息然后用 hashcat 爆破
本地RDP流量分析
在WireShark中导出PDU到文件,选择OSI Layer 7,保存为pcap文件,然后使用PyRDP导出为可识别类型。
1 | pyrdp-convert -o output rdp.pcap |
导出完成后启动GUI界面
1 | pyrdp-player |
即可看RDP的操作。
工控流量分析
参考连接:https://blog.csdn.net/song123sh/article/details/128387982
将流量按长度降序排列,然后在各层寻找线索,
显示分组字节,从base64后开始,然后解码看文件类型,最后显示成该类型
Modbus 协议分析
Modbus 流量主要有三类:Modbus/RTU、Modbus/ASCII、Modbus/TCP
Modbus/RTU
从机地址1B+功能码1B+数据字段xB+CRC值2B
最大长度256B,所以数据字段最大长度252B
Modbus/ASCII
由Modbus/RTU衍生,采用0123456789ABCDEF 表示原本的从机地址、功能码、数据字段,并添加开始结束标记,所以长度翻倍
开始标记:(0x3A)1B+从机地址2B+功能码2B+数据字段xB+LRC值2B+结束标记\r\n2B
最大长度513B,因为数据字段在RTU中是最大252B,所以在ASCII中最大504B
Modbus/TCP
不再需要从机地址,改用UnitID;不再需要CRC/LRC,因为TCP自带校验
传输标识符2B+协议标识符2B+长度2B+从机ID 1B+功能码1B+数据字段xB
一般题目考察 Modbus/TCP 比较多,然后主要考察的就是下面这种功能码(这里只列了部分)
因此解题的时候配合过滤器一个个功能码看过去就行
1:读线圈
2:读离散输入
3:读保持
4:读输入
5:写单个线圈
6:写单个保持
15:写多个线圈
16:写多个保持
例题1 HNGK-Modbus流量分析
使用下面这个过滤器命令即可得到 flag
1 | (((_ws.col.protocol == "Modbus/TCP") ) && (modbus.byte_cnt)) && (modbus.func_code == 16) |

flag{TheModbusProtocolIsFunny!}
S7comm 协议分析
西门子设备的工控协议,基于 COTP 实现,是COTP的上层协议
主要有三种类型:Job(1)、Ack_Data(3)/Ack(2)、Userdata(7)
Job:下发任务/指令
Ack_Data:带有返回数据
Ack:单纯确认,含有数据
Userdata:用户自定义数据区,也包含功能指令
例题1 2020ICSC湖州站—工控协议数据分析
首先过滤出S7协议的数据包,发现在一些Ack_Data的数据包中传输了二进制数据
因此,我们将所有带有二进制数据的数据包都过滤出来,发现一些Job的数据包中也有二进制数据
然后我们尝试将所有带有二进制数据的Job数据包都过滤出来并导出特定分组,过滤器代码如下
1 | ((s7comm) && (s7comm.resp.data)) && (s7comm.param.func == 0x05) |

然后使用 tshark 提取数据
然后使用 tshark 提取数据
1 | tshark -r 1.pcap -T fields -e s7comm.resp.data | uniq |

最后 CyberChef 解码二进制即可得到 flag
例题2 2020ICSC济南站—被篡改的数据
翻看流量包,发现很多 S7COMM 数据包,使用过滤器过滤,发现 s7comm.resp.data 字段传了很多 66 数据
使用过滤器过滤出传了 s7comm.resp.data 字段数据但数据不是 66 的 S7 数据包
发现了疑似 flag 的数据,为了防止 flag 中含有 f 字符而被过滤
因此我们使用下面这个过滤命令进行过滤,然后导出特定分组
1 | (((frame.number >= 19987 && frame.number <=20032) && (_ws.col.protocol == "S7COMM")) && (s7comm.param.func == 0x05)) && (s7comm.resp.data) |
最后 tshark 提取出数据,然后十六进制解码即可得到 flag:flag{93137ad4a}
例题3 枢网智盾2021—异常流分析
打开流量包,发现很多 S7comm 流量,然后稍微过滤一下,发现是写入数据的流量
然后写入的数据几乎都是 ffff 开头的,因此我们直接查看不是 ffff 开头的数据
1 | ((_ws.col.protocol == "S7COMM") && (s7comm.param.func == 0x05)) && (s7comm.resp.data[0:2] != ff:ff) |
即可得到 flag:flag{ffad28a0ce69db34751f}
例题4 枢网智盾2021—工控协议分析
1 | (_ws.col.protocol == "S7COMM") && (frame.number == 418) |

然后直接把明文传输的数据 base64 解码即可
flag{hncome66!}
蓝牙(OBEX)流量分析
在统计的协议分级中选中OBEX协议
然后查找pin的分组详情,获得压缩包的密码
邮件(STMP)流量分析
可以试试看导出对象-导出IMF-导出文件的后缀是eml(可以使用网易邮箱大师打开)
eml文件是将数据base64编码后再传输的,有些数据直接用邮箱软件打开可能看不到,建议手搓一遍
无线流量分析
在kali中用弱口令密码爆破出WIFI密码
执行命令:aircrack-ng ctf.pcap -w rockyou.txt
执行命令解码:airdecap-ng -p password1 ctf.pcap -e ctf -o 1.pcap
然后打开解码后的文件,查找flag
SLL、TLS加密流量分析
老版本的 wireshark 中显示的是 SSL,新版本的改成TLS了
解密方法就是点击 编辑 -> 首选项 -> Protocols -> TLS 加载 RSA 私钥 或 者加载日志文件
解完密后就和平常的流量分析一样了
例题-BUU 第九章TLS流量分析
打开流量包发现有 TLS 数据包,然后还有一些红黑条纹,猜测是被加密了
翻看流量包,追踪 TCP 流,发现流7中POST了一个 sslkey.log 日志文件

导出 sslkey.log 日志文件,然后按上面的步骤导入解密

解密完后直接搜索 flag{ 字符串即可找到 flag{e3364403651e775bfb9b3ffa06b69994}

例题-DDCTF2018 流量分析
直接在 TLS 加载 RSA 私钥解密即可
私钥的格式如下:
1 | -----BEGIN RSA PRIVATE KEY----- |
例题-2024铁三初赛 流量分析
PFX证书导入
如果题目给的是der和pfx证书,输入密码后新版本的wireshark可以直接作为TLS密钥使用,一般Windows证书都是用mimikatz导出的,那么密码就是mimikatz,其他情况需要pfx2john爆破一下。
MMTLS - 微信安全通信协议
article/基于TLS1.3的微信安全通信协议mmtls介绍.md at master · WeMobileDev/article
VPN流量分析
Shadowsocks流量分析
例题-2023强网杯-谍影重重3.0
1 | #请求解密脚本 |
VMess(V2ray)流量分析
VMessMD5
【例题:2022强网杯-谍影重重】
VMessAEAD
【例题:2024 DubheCTF-authenticated mess & unauthenticated less】
ADS-B流量分析
飞机/航空器流量,找到流量数据,用pyModeS模块分析即可
例题
[2023 强网杯] 谍影重重2.0
下载附件得到一个只有TCP流量的流量包
题目需要我们分析流量包找到飞机的飞机速度和飞机的 ICAO CODE
问了GPT得知飞机常见的协议中有ADS-B,然后在网上找到pyModeS这个模块
在参考链接:https://gitee.com/wangmin-gf/ads-b 看到了与tcp.payload中相似的数据
使用tshark提取出流量包中的数据,然后使用这个脚本批量解密找speed最快的即可
tshark -r attach.pcapng -T fields -e “tcp.payload” | sed ‘/^\s*$/d’ > tshark.txt
1 | import pyModeS |
1 | =========================================================================== |
损坏的流量包分析
例题-第一届“百度杯”信息安全攻防总决赛 find the flag(flag藏在 frame29-41 的 ip.id 字段中)
打开流量包后发现有如下的报错

可以直接使用 在线网站 修复
修复完成以后就是正常的流量分析了
从流量包中找异常流量
一般这种题目的做法就是,观察正常的流量包中的字段,毕竟一个流量包中正常的流量肯定占大多数,
然后结合过滤器,一个字段一个字段地进行排除,就是筛选出不等于正常字段值的流量。
内存取证
常见文件后缀:.vmem / .dump / .raw / .img
内存取证除了常用的 Vol 以外,也可以尝试一下 R-Stdio 这个工具,提取文件的时候不一定哪个可以用
打开 R-Stdio -> 驱动器 -> 打开镜像 -> 扫描
也可以直接010手提,如果做不出来的时候可以foremost提取一下,说不定会有奇效(2024网鼎杯你说是吧)


vol.py –info 可以查看插件
1 | #官方WIKI |
Windows内存取证
不是Windows10的内存镜像的话可以直接用 Vol_all_in_one 一键分析
取证过程中一定要记得查看镜像桌面上的文件!
Volatility2
1 | Volatility Foundation Volatility Framework 2.6 |
1 | # 识别操作系统的基本信息 |
Volatility3
识别内存的系统版本(这个有时候vol3识别不出来,但是vol2可以)
1 | vol3.py -f dacong.raw banners.Banners |
如果是windows10的内存镜像的话,vol2的某些功能可能用不了,因此需要vol3(例:2023 安洵杯 dacongのWindows)
1 | # 查看命令 |
一些特殊进程
便签:StikyNot.exe (.snt 文件路径在C:\Users\XXX\AppData\Roaming\Microsoft\Sticky Notes\)【这个文件需要用Win7的便签或者记事本打开】
画图:mspaint.exe(这个进程可以用 memdump 导出 dmp 文件,然后改后缀为.data拖入Gimp中调整位移和分辨率,例:2024 NKCTF)
联系人:wab.exe (.contact 文件)
一些特殊文件
evtx - Windows系统日志
dat - 无法导出可以加上 -u 参数:volatility -f mem.data dumpfiles -r pdf$ -i –name -D dumpfiles/ -u
Linux内存取证
取证过程中一定要记得查看镜像桌面上的文件!
制作 Profile(Vol2) 的详细过程
Identify the profile for Linux
1 | strings mem | grep -i 'Linux version' | uniq |
1 | Linux version 5.10.0-21-amd64 (debian-kernel@lists.debian.org) (gcc-10 (Debian 10.2.1-6) 10.2.1 20210110, GNU ld (GNU Binutils for Debian) 2.35.2) #1 SMP Debian 5.10.162-1 (2023-01-21) |
Tips: Ubuntu 22.04 目前是不支持用 Vol2 进行取证的,必须使用 Vol3
1 | # 例题:2022 Sekai CTF | symbolic-needs 1 |
Try to find profile on Github
如果找不到需要的profile,就需要进行下面的步骤,自己手动制作profile了
Make the profile by yourself
一个profile的结构如下:其实一共就两个文件
1 | Debian5010\boot\System.map-2.6.26-2-amd64 |
这里以 Linux version 5.10.0-21-amd64 这个内核为例
示例项目已开源在 Lunatic的Github仓库
参考资料:巨魔大佬的博客
首先要到 官方仓库下载以下几个文件
1 | linux-headers-5.10.0-21-amd64_5.10.162-1_amd64.deb |
然后解压 linux-image-5.10.0-21-amd64-dbg_5.10.162-1_amd64.deb 这个文件
将下面这个文件复制出来
1 | linux-image-5.10.0-21-amd64-dbg_5.10.162-1_amd64\data\usr\lib\debug\boot\System.map-5.10.0-21-amd64 |
然后用 Docker 构建镜像制作 dwarf 文件,用于构建的 Dockerfile 文件如下:修改自巨魔的开源项目
Tips:使用前需要把上面那四个文件放到 Dockerfile 同一目录下,构建好后进入容器,dwarf 文件在/app目录下
1 | FROM debian:11.8 |
1 | docker build --tag profile . |
SSH连接容器映射出来的端口,将 dwarf 文件复制出来,然后和之前的 systemmap 文件一起打包为 Debian_5.10.0-21-amd64_profile.zip
最后将这个 zip 文件放到 ~/volatility/volatility/plugins/overlays/linux/ 路径下即可
使用 vol.py –info | grep Profile | grep Linux 命令查看 profile 是否成功加载

制作 symbols(Vol3) 的详细过程
识别内存镜像的系统版本
1 | strings mem | grep -i 'Linux version' | uniq |
1 | Linux version 5.4.0-100-generic (buildd@lcy02-amd64-002) (gcc version 9.3.0 (Ubuntu 9.3.0-17ubuntu1~20.04)) |
然后要找到和这个系统版本一模一样的内核,注意一定要一模一样
内核文件类似于下面这样
1 | linux-image-unsigned-5.4.0-100-generic-dbgsym_5.4.0-100.113_amd64.ddeb |
Ubuntu的内核可以去这个网站上找:https://launchpad.net/ubuntu/+source/linux/5.4.0-100.113
找到内核文件之后的操作可以使用Lunatic师傅写的 Dockerfile 辅助完成
1 | FROM ubuntu:20.04 |
1 | docker build --tag profile . |
SSH连接容器映射出来的端口,然后将json文件放到 volatility3/volatility3/framework/symbols/linux/ 目录下即可
Volatility2
1 | # 查看Profile是否载入成功 |
Volatility3
1 | # 查看当前都有哪些 Profile 可用 |
1 | linux.bash.Bash Recovers bash command history from memory. |
MacOS内存取证
Volatility2
Volatility3
识别不出内存镜像版本的取证
直接使用 010 手搓或者用 Strings 命令把可打印字符保存到文本文件中再手搓
需要从内存中找到 AES 解密的 key 的情况:可以使用 findaes.exe 工具辅助查找

用来制作内存镜像的工具
1、Volatility
2、FTK Imager
3、Magnet RAM Capture
4、Belkasoft Live RAM Capturer
5、WinPMEM
6、Rekall
7、DumpIt
8、OSForensics
dmp文件
1、拉入Passware Kit Forensic-Memory Analysis进行分析(用户名和密码)
2、使用vol分析
dump文件
1 | "dmp" 通常特指 Windows 的崩溃转储文件,而 "dump" 是一个更为通用的术语,可以用于描述各种数据转储操作或文件。 |
取证方法大致和dmp文件相同
mem文件
1 | vol.py -f mem imageinfo |
raw文件
可以直接使用 vol2 或者 vol3 进行内存取证
磁盘取证
Tips:1、同一个镜像文件,不同的密码可以挂载出不同的盘,里面的数据也不同
VeraCrypt
解密&挂载磁盘的步骤:
1.选择要挂载的加密盘,然后选择一个没有被占用的盘符再点击左下角的加载

2.输入加密盘的密钥,或者直接使用密钥文件(图片文件也可以)
如果这里加载失败,可以点击下面的加密卷工具,把密钥给改了,然后使用自己更改后的密钥挂载
取证大师
没啥好说的,直接把硬盘镜像文件拉进去梭就行
fat文件
1 | FAT格式: 即FAT16,这是MS-DOS和最早期的Win 95操作系统中最常见的磁盘分区格式。它采用16位的文件分配表,能支持最大为2GB的分区,几乎所有的操作系统都支持这一种格式。 |
1、可以使用veracrypt挂载到本地,然后用资源管理器打开
2、如果挂载后资源管理器打不开,可以使用winhex-工具-打开磁盘查看
VMDK文件
可以用Imdisk挂载到本地
1、可以使用Diskgenius-磁盘-打开虚拟磁盘文件
2、可以使用Imdisk挂载到本地,然后用everything进行搜索
3、可以使用7zip打开然后解压缩
4、可以使用FTK、Vera挂载
E01文件
1、若有BitLocker加密并提供了内存镜像,就拉入Passware Kit Forensic-Decrypt Disk-BitLocker进行爆破解密
解密后会得到一个G-decrypted.dd,然后用 FTK image 打开
2、提供的 E01 文件可能有好几部分,BitLocker加密的密钥可能藏在其中一部分中,建议用 FTK image 查看一下
FTK image 直接提取文件可能会有点问题(加密压缩包、根目录文件看不到),建议还是直接 mount 到本地然后再提取
3、高版本FTK报错可以试试低版本,4.2比较稳定
ad1文件
ad1文件是用 FTKimage 制作的磁盘镜像,因此可以使用 FTKimage 进行挂载
VHD文件
vhd 是 Virtual Hard Disk 虚拟磁盘的缩写,是一种用于存储虚拟机磁盘镜像的文件格式
可以在 Windows 系统下直接挂载,也可以拉入 DiskGenius 打开查看
如果有Bitlocker可以使用x-way提取一个.dd文件再进行爆破,新版本的Elcomsoft Forensic Disk Decryptor支持.vhd格式直接解Bitlocker
磁盘取证的一些思路
查看Powershell的历史记录
用户的powershell历史记录会保存在这个路径下
\Users\test\AppData\Roaming\Microsoft\Windows\PowerShell\PSReadLine\ConsoleHost_history.txt
仿真取证
使用FTK Imager + VMware就行,Hyper-V的兼容性问题还有待考证
【电子取证:镜像仿真篇】DD、E01系统镜像动态仿真 - ldsweely - 博客园
步骤:
- 以管理员形式打开vm
- 新建虚拟机
- 自定义
- 稍后安装
- 选择你的系统
- 选择安装位置
- BIOS
- 自己分配处理器和内存(如果有时候蓝屏则调高内存或许可行
- 默认(NAT)
- 默认(推荐)
- SATA
- 使用物理磁盘
- 设备选择刚刚挂载的PhysicalDrive
- 下一步
网站取证
1、直接拿D_safe扫描可疑文件
服务器取证
硬盘镜像文件后缀: .qcow2
Mysql5.7 数据库从qp.xb文件恢复数据
需要安装并使用qpress和xtrabackup
1 | wget "http://docs-aliyun.cn-hangzhou.oss.aliyun-inc.com/assets/attach/183466/cn_zh/1608011575185/qpress-11-linux-x64.tar" |
1 | chmod 775 qpress |
其他
1、磁盘恢复
拉到 kali 中用 extundelete
extundelete –restore-all disk-image
之后在所在目录会生成一个恢复文件
2、浏览器登录凭证破解
Firefox登录凭证破解
使用Firepwd工具破解,将key4.db、logins.json复制到firepwd目录下,用firepwd.py破解
1 | python firepwd.py logins.json |
其他题目
FAS文件
AutoCAD插件的一个中间文件格式,可以反编译(2024 赣育杯)
fas文件格式研究 - AutoLISP/Visual LISP 编程技术 - AutoCAD论坛 - 明经CAD社区 - Powered by Discuz!
Hopfengetraenk/Fas-Disasm: Fas-Disassembler/Decompiler for AutoCAD Visual Lisp